
A robotika iparának van egy piszkos kis titka: bármilyen hasznos dologra megtanítani egy robotot gyötrelmesen lassú és csillagászati összegeket emészt fel. Évekig az uralkodó nézet az volt, hogy nyers erővel próbáljunk intelligenciát beletuszkolni a Vision-Language-Action (VLA) modellekbe, amelyek több tízezer órányi emberi, aprólékos bábjátékos irányítást igényelnek minden elképzelhető feladaton keresztül. Ez egy gigantikus adat-szűk keresztmetszet.
Most a 1X robotikai cég egy olyan megoldással állt elő, ami szinte istenkáromlással ér fel. Új megközelítésük a NEO humanoid robot számára megtévesztően egyszerű: hagyjuk a kínos leckéket, és engedjük, hogy a robot az emberi viselkedés hatalmas, kaotikus és végtelenül tanulságos könyvtárából, az internetről tanuljon. Ez nem csupán egy frissítés; ez egy alapvető paradigmaváltás abban, ahogyan egy robot képességeket szerezhet.
A tegnap adatéhes szörnyetege
Hogy igazán felmérjük, mekkora ugrást tesz az 1X, meg kell értenünk a status quót. A legtöbb modern alapmodell a robotikában, a Figure Helix-étől az Nvidia GR00T-jéig, VLA. Ezek a modellek erősek, de csillapíthatatlanul éhesek a magas minőségű, robot-specifikus demonstrációs adatokra. Ez azt jelenti, hogy embereket kell fizetni, hogy több ezer órán keresztül távirányítással működtessék a robotokat, hogy gyűjtsenek példákat például egy csésze felemelésére vagy egy törölköző összehajtogatására.
Ez a megközelítés komoly akadályt jelent az igazán általános célú robotok létrehozásában. Drága, rosszul skálázódik, és a kapott modellek sérülékenyek lehetnek, elbuknak, ha olyan tárggyal vagy környezettel találkoznak, amit még sosem láttak. Mintha egy gyereket úgy próbálnánk meg főzni tanítani, hogy csak a saját konyhánkban nézhet minket, ahelyett, hogy végignézné az összes valaha készült főzőműsort.
Álmodjunk egy kicsit… házimunkáról
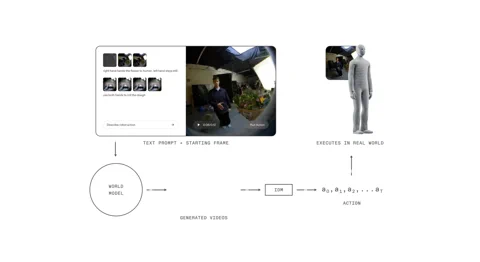
Az 1X World Model (1XWM) az egész eddigi forgatókönyvet a kukába hajítja. Ahelyett, hogy közvetlenül leképezné a nyelvet cselekvésekre, szöveg által kondicionált videógenerálást használ, hogy kitalálja, mit tegyen. Ez egy két részből álló agy, amely gyakorlatilag lehetővé teszi a robotnak, hogy elképzelje a jövőt, mielőtt cselekedne.
Először is, ott van a Világmodell (WM), egy 14 milliárd paraméteres generatív videómodell, amely a rendszer képzelőerejeként funkcionál. Adsz a NEO-nak egy szöveges utasítást – „csomagold ezt a narancsot az uzsonnás dobozba” – és a WM, a jelenlegi jelenetre tekintve, álmodik egy rövid, hihető videót a feladat elvégzéséről.
Aztán az Inverz Dinamikai Modell (IDM), a gép pragmatikusa, elemzi ezt az álmot. Lenyűgöző pontossággal lefordítja a generált pixeleket egy konkrét motorparancs-sorozattá, áthidalva a vizuális mit és a fizikai hogyan közötti szakadékot. Ezt a folyamatot egy többlépcsős képzési stratégia alapozza meg: a modell webes méretű videókkal indul, majd 900 órányi egocentrikus emberi videón tréningezik tovább, hogy első személyű perspektívát kapjon, végül pedig mindössze 70 órányi NEO-specifikus adaton finomhangolják, hogy alkalmazkodjon a saját testéhez.

Egy ügyes trükk a képzési pipeline-jukban a „felirat-feljavítás” (caption upsampling). Mivel sok videó adatkészlet szűkszavú leírással rendelkezik, az 1X egy VLM-et használ gazdagabb, részletesebb feliratok generálására. Ez tisztább kondicionálást biztosít és javítja a modell képességét a komplex utasítások követésére – egy technika, amely hasonló előnyöket mutatott az olyan képmodelleknél, mint az OpenAI DALL-E 3-ja.
A humanoid előny
Ez az egész videó-központú megközelítés egy kritikus, és talán nyilvánvaló, hardverelemen múlik: a robot emberi alakú. Az 1XWM, amely számtalan órányi emberi interakción képződött a világgal, mély, implicit megértést fejlesztett ki a fizikai priorokról – gravitáció, lendület, súrlódás, tárgyak affordanciái –, amelyek közvetlenül átvihetők, mert a NEO teste alapvetően emberi módon mozog.
Ahogy az 1X fogalmaz, a hardver „elsőrangú állampolgár az AI stackben”. A NEO és az ember közötti kinematikai és dinamikai hasonlóságok azt jelentik, hogy a modell tanult priorjai általában érvényesek maradnak. Amit a modell vizualizálni tud, azt a NEO többnyire meg is tudja valósítani. A hardver és a szoftver szoros integrációja bezárja a gyakran áruló, szimuláció és valóság közötti szakadékot.
Elméletből valóság (némi botladozással)
Az eredmények meggyőzőek. Az 1XWM lehetővé teszi a NEO számára, hogy általánosítson olyan feladatokra és tárgyakra, amelyekre egyáltalán nem kapott közvetlen képzési adatot. A promóciós videóban ing vasalása gőzzel, növény öntözése, sőt még egy WC-ülőke kezelése is látható – egy olyan feladat, amelyre nem volt korábbi példája. Ez arra utal, hogy a kétkezes koordinációhoz és a komplex tárgyinterakcióhoz szükséges tudás sikeresen áttevődik az emberi videóadatokból.
De ez nem varázslat. A rendszernek megvannak a maga korlátai. A generált „rolloutok” „túlságosan optimisták” lehetnek a sikerrel kapcsolatban, és a monokuláris előképzés gyenge 3D-s megalapozottsághoz vezethet, ami miatt a valódi robot alálő vagy túllő egy célon, még akkor is, ha a generált videó tökéletesnek tűnik. Az olyan ügyességi feladatok, mint a gabonapehely öntése vagy egy mosolygós arc rajzolása, továbbra is kihívást jelentenek.
Az 1X azonban talált egy ígéretes módszert a teljesítmény növelésére: a tesztidőbeli számítási kapacitást. Egy „húzz ki egy zsebkendőt” feladatnál a sikerességi ráta 30%-ról 45%-ra ugrott, amikor a rendszernek megengedték, hogy nyolc különböző lehetséges jövőt generáljon, és kiválassza a legjobbat. Bár ez a kiválasztás jelenleg manuális, egy olyan jövőre mutat, ahol egy VLM értékelő automatizálhatná a folyamatot, jelentősen javítva a megbízhatóságot.
Az önfejlesztő lendkerék
Az 1XWM többet jelent, mint egy egyszerű, lépésenkénti frissítés; ez egy potenciális paradigmaváltás, amely szélesre tárhatja az adat-szűk keresztmetszetet. Létrehoz egy önfejlesztő lendkereket. Mivel képes széles körű feladatokat megpróbálni nem nulla sikerességi rátával, a NEO most már saját adatait is generálhatja. Minden cselekedet, legyen az siker vagy kudarc, új képzési példává válik, amelyet visszatáplálhatnak a modellbe a stratégiájának finomítására. A robot elkezdi önmagát tanítani.
Természetesen komoly akadályok maradnak. A WM jelenleg 11 másodpercet vesz igénybe egy 5 másodperces terv generálásához, plusz még egy másodpercet az IDM-nek a cselekvések kinyerésére. Ez a késleltetés örökkévalóság egy dinamikus, valós környezetben, és elképzelhetetlen reaktív feladatokhoz vagy finom, érintésgazdag manipulációhoz.
Mégis, az adatproblémát fejest ugorva, az 1X talán épp most tárta fel az ajtót egy olyan jövő felé, ahol a robotok nem a mi fárasztó utasításainkból, hanem a kollektív, rögzített tapasztalatunkból tanulnak. Ez a jövő felgyorsul, internetes videóról internetes videóra.
