
A Google DeepMind lerántotta a leplet a Gemini Robotics-ER 1.6-ról, az “Embodied Reasoning” (megtestesült érvelés) modelljük legfrissebb iterációjáról, aminek egyetlen célja van: felvértezni a robotokat azzal a józan paraszti ésszel, ami eddig annyira hiányzott belőlük a fizikai világban. Az új modell látványosan javítja a robotok képességét a környezetük érzékelésére, megértésére és az azzal való interakcióra, így a gépek túllépnek a gépies parancskövetésen, és elkezdenek valóban logikusan gondolkodni a feladataikról.
A Gemini Robotics-ER 1.6 egyik legfontosabb újítása a továbbfejlesztett vizuális és térbeli érzékelés, amit a fejlesztők a “mutogatás” (pointing) képességével szemléltettek. Ha megkérjük a robotot, hogy keressen meg egy konkrét szerszámot egy kaotikus műhelyben, a modell már képes pontosan beazonosítani, megszámolni és tűpontosan megjelölni a keresett tárgyat, miközben elegánsan figyelmen kívül hagyja a zavaró tényezőket. Ez nem csupán egyszerű tárgykeresés; ez a komplex térbeli logika alapköve, legyen szó a tökéletes fogáshoz szükséges röppálya kiszámításáról vagy olyan relatív parancsok értelmezéséről, mint a “tedd a villáskulcsot a szerszámosládába”. A modell még a fizikai korlátokat is átlátja: képes például kiválogatni az összes olyan tárgyat, ami méreténél fogva befér egy adott tárolóba.
A modell a robotika egyik örök rákfenéjére is megoldást kínál: honnan tudja a gép, hogy tényleg végzett-e a melóval? A fejlett, többnézetű érvelésnek (multi-view reasoning) köszönhetően a Gemini Robotics-ER 1.6 képes több kamera – például egy felső és egy csuklóra szerelt egység – élőképét egyetlen koherens egésszé gyúrni. Ez megakadályozza, hogy a robot végtelen ciklusba ragadjon, vagy elbukjon egy feladatot csak azért, mert egy tárgy az egyik nézőpontból éppen takarásban van.
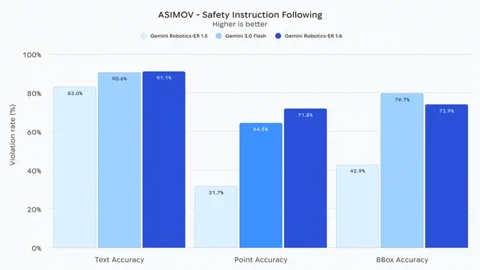
Miért akkora szám ez?
Ez a frissítés sokkal több, mint egy szimpla teljesítménynövekedés; ez az autonómia alapköveinek lerakása. Az analóg mérőműszerek leolvasása, a különböző kameraforrások összehangolása és a bonyolult térbeli összefüggések megértése az, ami elválasztja a buta gyári robotkart egy valóban hasznos, terepen is bevethető robottól. A DeepMind hivatalos bejelentése szerint ez az eddigi legbiztonságosabb robotikai modelljük.
Ami talán a legkritikusabb pont, hogy a Gemini Robotics-ER 1.6 “jelentősen fejlődött” a fizikai biztonsági korlátok betartásában. Megérti az olyan utasításokat, mint a folyadékok elkerülése vagy a 20 kg-nál nehezebb tárgyak emelésének tilalma. A bázismodellként szolgáló Gemini 3.0 Flash-hez képest állítólag 10%-kal hatékonyabban ismeri fel a videókban az emberi sérülés kockázatát. Ez a biztonsági fókusz és a valós idejű logikai következtetés elengedhetetlen lépés afelé, hogy a robotok megbízhatóan és biztonságosan működhessenek a kiszámíthatatlan emberi környezetben. A modell a fejlesztők számára már elérhető a Gemini API-n és a Google AI Studión keresztül.
